Why I Built My Own Model Routing Engine
How I replaced static model assignments with an autonomous routing engine, shadow testing pipeline, and live dashboard for a 25-agent orchestration platform.
Key takeaway
The real cost of AI is not the per-token price. It is the cost of retries, mediocre output, and human cleanup when the wrong model handles the task.
I run an AI agent orchestration platform called OpenClaw. It coordinates 25 agents across nine providers and 17 models, handling everything from code generation to governance to content strategy. It sounds impressive until you realise every single one of those agents was hard-coded to a specific model at deployment time. That was the reality I walked into on a Friday morning, and by the end of the day I had a fully autonomous routing engine, a shadow testing pipeline, and a live dashboard. Here is how it happened, why I ignored the obvious shortcuts, and what I learned along the way.
The Problem: Static Model Assignments Do Not Scale#
When you start building multi-agent systems, you pick a model and move on. Opus 4.6 for the important stuff, something cheaper for the housekeeping tasks. It works fine when you have three agents.
OpenClaw grew organically. Agents were added as needs emerged, each one assigned a model based on what seemed right at the time. At 25 agents, that approach falls apart. The landscape shifts weekly. New models drop, pricing changes, context windows expand. I had agents running expensive models for tasks that a model costing a tenth of the price could handle just as well. Other agents were stuck on budget models when their workload had evolved to need something with more reasoning capability.
The real cost of static assignments is the dollar figure on your monthly invoice plus the invisible cost of retries, of mediocre output that needs human cleanup, of an agent that takes three attempts at a coding task because the model assigned to it was chosen six months ago when requirements were different.
A $3 per million token model that completes a task in one shot is cheaper than a $0.28 per million model that needs three attempts and still produces something you have to fix. I had no way to measure that, let alone optimise for it.
The Temptation: Just Use a Third-Party Router#
The first suggestion I got was to reach out to existing routing tools. LiteLLM, various commercial routing layers, abstraction frameworks that promise to solve this exact problem. The pitch is always the same: drop in our library, point your agents at our proxy, and we will handle model selection for you.
I have a deep allergy to this approach.
When you hand model routing to a third party, you are handing over one of the most consequential decisions in your entire AI stack. Which model handles which task directly affects quality, cost, latency, and reliability. That is a decision I want to see, modify, and audit. I do not want it abstracted behind someone else's algorithm.
There are practical concerns too. Another dependency means another point of failure. Another API key to manage. Another vendor's pricing to track. Another changelog to monitor for breaking changes. When something goes wrong at 2am, I want to read my own code, not file a support ticket.
The other issue is context. A generic routing tool does not know that OpenClaw's finance agent needs reasoning capability but the monitoring agent just runs health checks. It does not know that the content agents benefit from a specific model's writing style, or that the dev team orchestrator needs to spawn sub-agents on different models than itself. That context is mine. It belongs in my system, not in a Software as a Service (SaaS) product's configuration panel.
Build the things that are core to your system. Use off-the-shelf for the things that are not. Model routing, for a multi-agent platform, is core.
The Solution: A Custom Routing Intelligence Layer#
I built four components that plug directly into OpenClaw's agent lifecycle and work together as a closed loop.
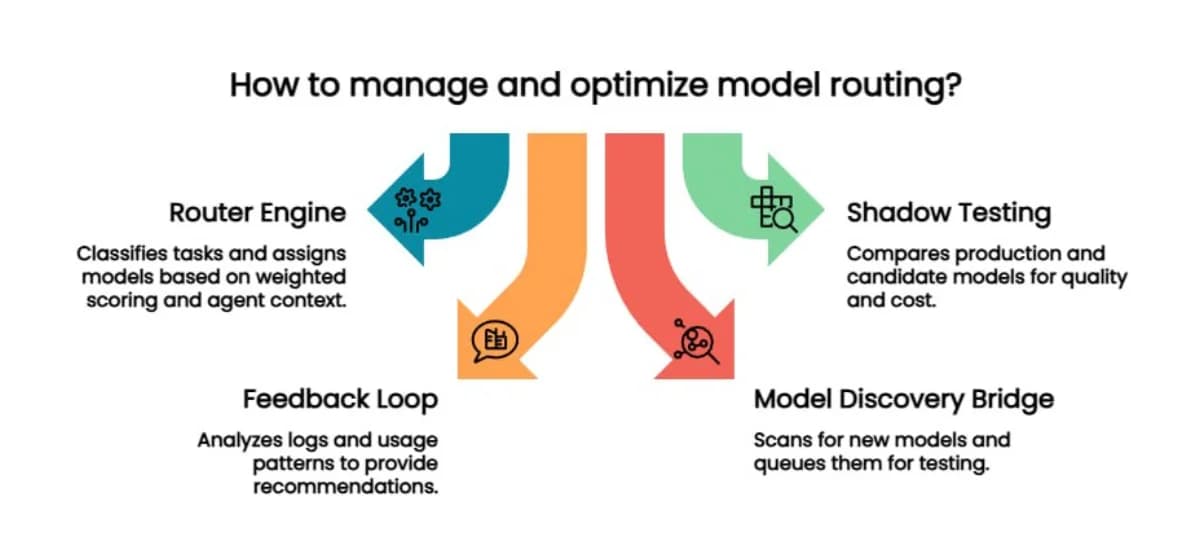
1. The Router Engine#
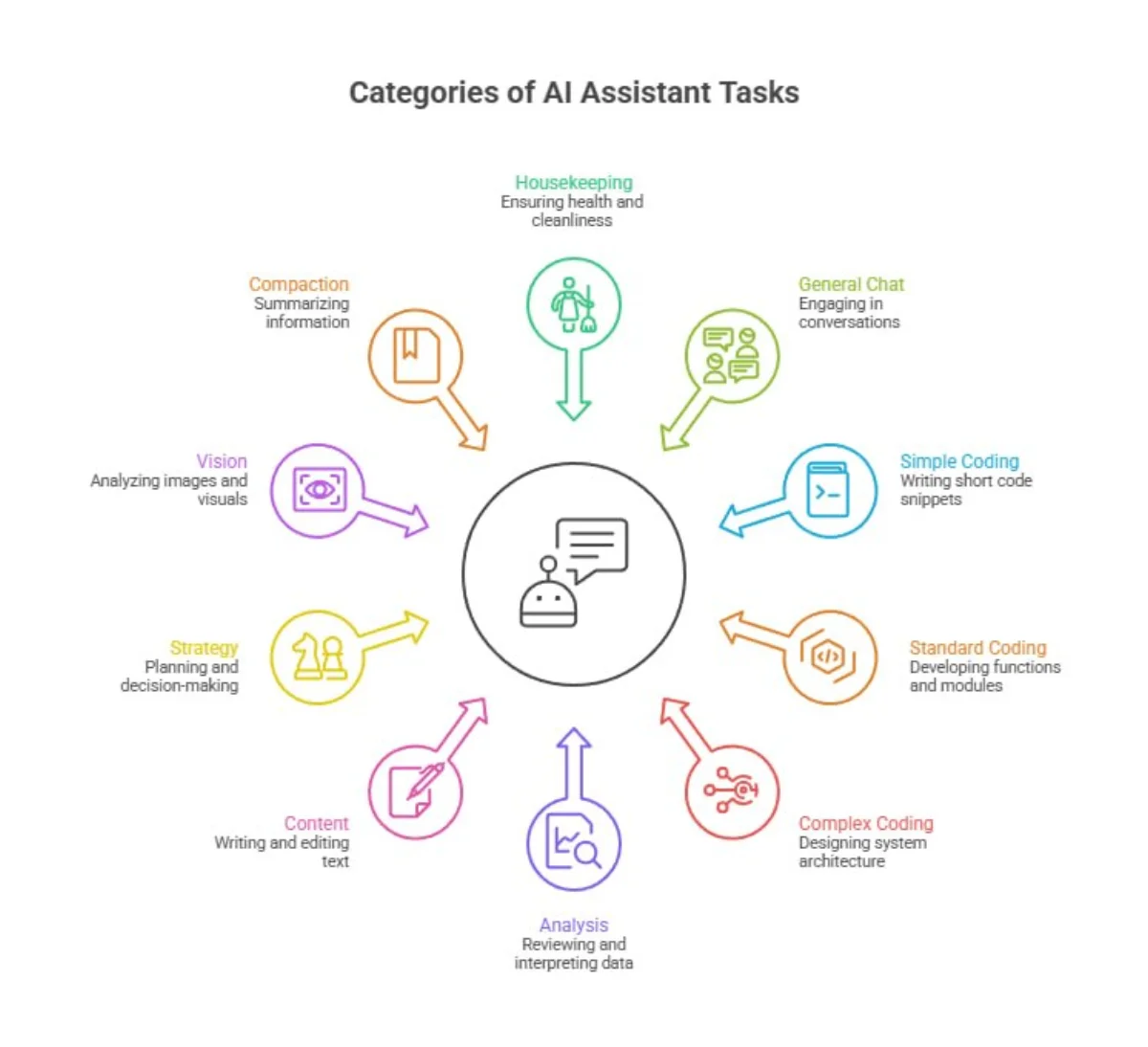
A task classifier categorises every incoming request into one of ten categories: housekeeping, general chat, simple coding, standard coding, complex coding, analysis, content, strategy, vision, and compaction. It uses weighted keyword scoring against the message content, combined with agent role context and current budget position.
Each agent has a role mapping with a locked minimum. The monitoring agent cannot be downgraded below a fast, cheap model. The development agent cannot be pushed below a model that handles complex code well. These floors prevent the optimiser from making false economies.
Every routing decision is logged as structured JSON Lines (JSONL) with the timestamp, agent, category, selected model, confidence score, and whether an escalation occurred.
2. Shadow Testing#
When a new model appears that could potentially replace a current assignment, the shadow tester sends the same prompt to both the production model and the candidate. It compares the results on quality, completion, and cost, then makes a recommendation: promote, reject, or inconclusive.
No model gets promoted into a production role without evidence. This is the difference between chasing the latest release and making informed decisions.
3. The Feedback Loop#
A weekly analysis runs across all routing logs. It looks at which models are being used, where escalations are happening, which categories are costing the most, and whether any assignments look suboptimal based on actual usage patterns. The output is a set of recommendations, not automatic changes. The system is transparent about what it thinks should change and why.
4. Model Discovery Bridge#
A daily scan checks for new models across providers. When it finds something that is genuinely cheaper in the same capability category, or a meaningful version upgrade, it queues the candidate for shadow testing. The pipeline feeds itself. Discovery finds candidates, shadow testing evaluates them, the feedback loop measures the impact.
The Dashboard#
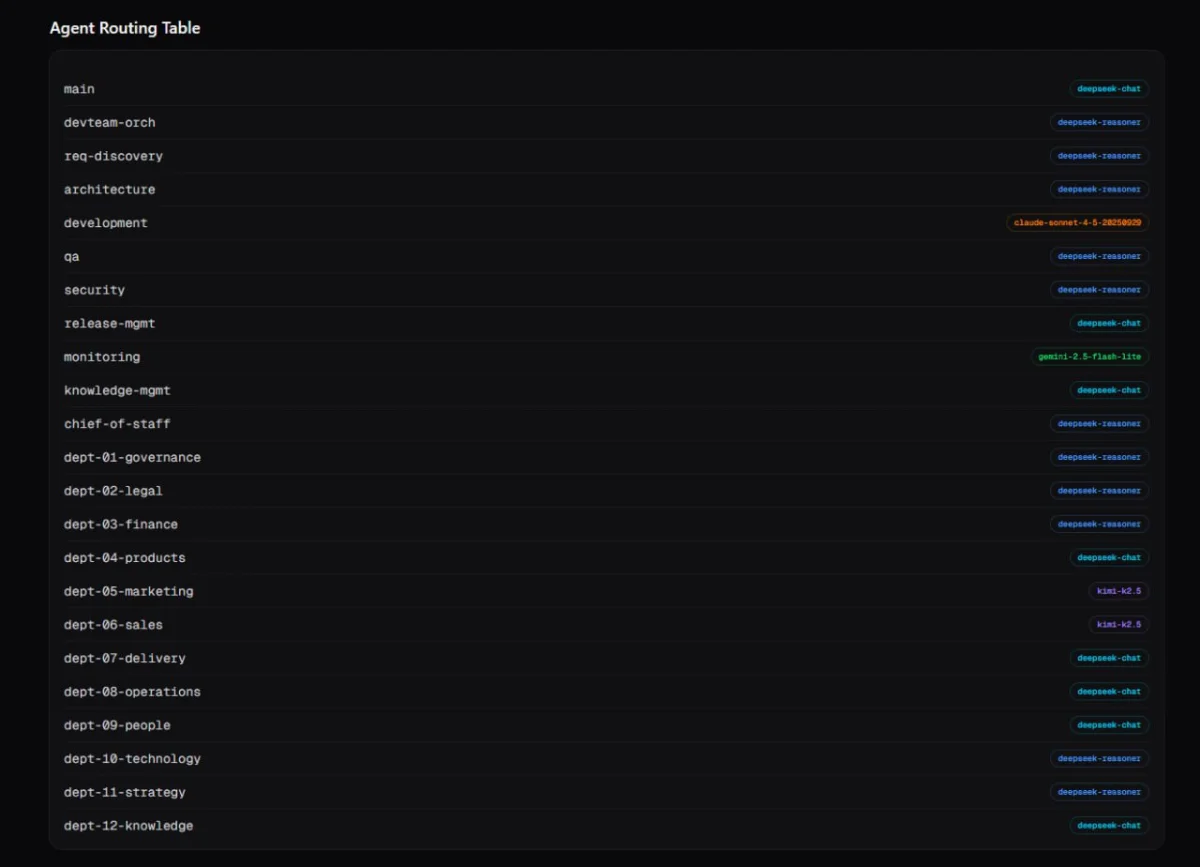
All of this is visible through a live dashboard with 30-second auto-refresh. Agent routing table, model distribution, cost history, infrastructure health, shadow test queue and results, model discovery with provider coverage. If I want to know why a particular agent is using a particular model, the answer is one click away.
The dashboard is not a nice-to-have. Without visibility, you are flying blind. Every automated system needs a window into what it is actually doing.
Expected Outcomes#
I have been running this on OpenClaw for less than a day, so hard metrics will come later. But the architecture is designed to deliver three things.
Lower effective cost. Not lower sticker price per token, but lower cost per completed task. The routing engine picks the cheapest model that can actually do the job, factoring in the real cost of retries and quality issues with underpowered models.
Better quality matching. Reasoning-heavy tasks go to reasoning models. Simple housekeeping goes to the cheapest option. Content writing goes to models with strong natural language output. Previously this was all manual guesswork.
Self-improvement over time. The feedback loop and shadow testing pipeline mean the system gets better without manual intervention. As new models appear and pricing shifts, the routing adapts. The weekly analysis catches drift before it becomes a problem.
What I Would Do Differently#
If I were starting fresh, I would build the logging infrastructure first. Structured JSONL logs for every routing decision turned out to be the foundation that everything else depends on. The feedback loop, the dashboard, the cost analysis, they all read from the same log files. I built the router first and added logging as an afterthought, then had to retrofit it. Start with the logs.
I would also set up the dashboard earlier in the process. Being able to see what the routing engine is doing while you are building it saves a lot of debugging time compared to reading raw JSON in a terminal.
Related Reading#
- AI Agents and Timezone Configuration — How OpenClaw handles scheduling complexity across distributed agents
The Bigger Point#
The Intelligence Age is creating pressure to adopt AI faster and at larger scale. Multi-model, multi-agent systems are becoming common. The question of which model handles which task is no longer a one-time decision you make during setup. It is an ongoing operational concern that directly affects your costs, quality, and reliability.
You can outsource that decision to a third party, or you can own it. I chose to own it, and I would make that choice again. The code is not complicated. The architecture is not novel. But it is mine, I understand every line of it, and when something needs to change at 2am on a Sunday, I know exactly where to look.
Build the things that matter. Buy the things that do not. Know which is which.
Mark Smith is the founder of Cloverbase, an AI strategy consultancy based in Whangārei Heads, New Zealand.
Short link to this post: m1.nz/a2a6d6d
Comments
Loading...